Machine learning is a subfield of artificial intelligence that involves the development of algorithms and models that can learn from and make predictions or decisions based on data. There are many different types of machine learning algorithms, each with their own strengths and weaknesses, and they can be applied to a wide variety of problems.
Decision trees
One of the most popular and widely used types of machine learning algorithms is decision trees. Decision trees are a type of algorithm that can be used for both classification and regression problems. They work by recursively partitioning the data into subsets based on the values of the input features, and making predictions based on the majority class or mean value of the observations in each subset.

Here’s an example of how decision trees can be implemented in R:
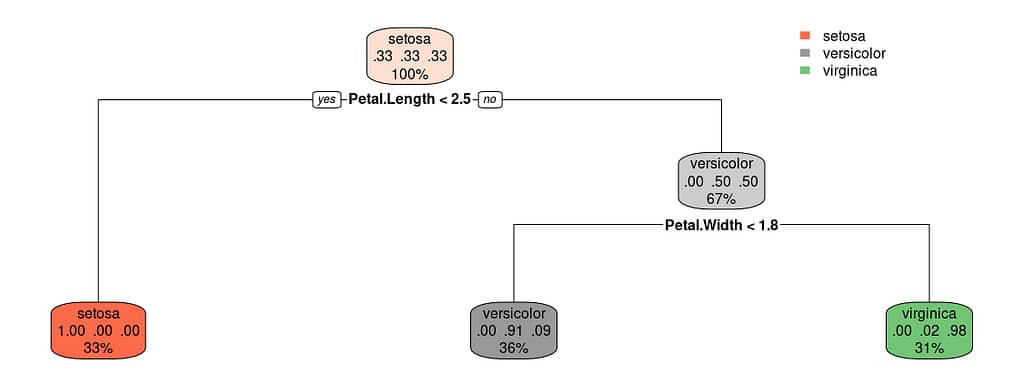
In this example, we are using the iris dataset, a popular dataset for classification problems that contains measurements of sepals and petals of three different species of irises. We are using all the columns as predictors and the species as response. The rpart function is used to build the decision tree model, and the rpart.plot is used to plot the tree.
We can do the same thing in Python:
The train_test_split() function is used to split the data into a training set and a test set, the DecisionTreeClassifier() function is used to build the decision tree model and the fit function is used to train the model. The predict function is used to make predictions on the test set, and the accuracy_score() function is used to evaluate the model’s performance by comparing the predicted values to the actual values.
Linear models
Another popular type of machine learning algorithm is linear regression. Linear regression is a type of algorithm that can be used for continuous target variables and it attempts to find the best linear relationship between the input features and the target variable.
Here’s an example of how linear regression can be implemented in R:
In this example, we are using the mtcars dataset, a dataset that contains measurements of different cars such as the miles per gallon, weight, and horsepower. We are using the weight and horsepower as predictors and the miles per gallon as the target variable. The lm() function is used to build the linear regression model and the summary function is used to summarize the model.
We can also run linear regressions in Python:
In this example, we are using the mtcars dataset from this Gist. The predictors are the weight and horsepower and the target variable is the miles per gallon. The train_test_split() function is used to split the data into a training set and a test set, the LinearRegression() function is used to build the linear regression model, and the fit function is used to train the model. The predict function is used to make predictions on the test set, and the mean_squared_error() function is used to evaluate the model’s performance by comparing the predicted values to the actual values.
Artificial neural networks (ANNs)
Finally, another popular type of machine learning algorithm is artificial neural networks (ANNs). Artificial neural networks are a type of algorithm that are inspired by the structure and function of the human brain. They are composed of layers of interconnected “neurons” that process and transmit information. They are highly flexible and can be used for a wide variety of problems, including image and speech recognition, natural language processing, and more.


Here’s an example of how ANNs can be implemented in R using the caret package:
In this example, we are again using the iris dataset, but this time we are splitting the data into a training set and a test set. We are using all the columns as predictors and the species as response. The train function is used to build the ANN model, specifying the “mlp” method for neural networks, and using k-fold cross validation with k=5 to train the model. The predict function is used to make predictions on the test set, and the confusionMatrix() function is used to evaluate the model’s performance by comparing the predicted values to the actual values.
In Python:
This example again uses the iris dataset. We are using all the columns as predictors and the species as response. The train_test_split() function is used to split the data into a training set and a test set, the MLPClassifier() function is used to build the ANN model, the fit function is used to train the model, the predict function is used to make predictions on the test set, and the accuracy_score() function is used to evaluate the model’s performance by comparing the predicted values to the actual values.
Machine learning is a powerful tool that can be used to extract insights from data and make predictions and decisions. There are many different types of machine learning algorithms, each with their own strengths and weaknesses, including decision trees, linear regression, and artificial neural networks. These examples in R demonstrate how to implement these algorithms, but it’s important to note that the performance of these models may vary depending on the specific problem and the quality of the data. It’s also important to understand the underlying concepts of each algorithm and the assumptions they make, to make the right choice for a given problem.