Mean: the average measurement from a sample
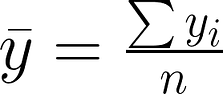
ȳ = sample mean
Σ = sum
yi = ith observation
n = sample size
Changing scale
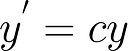
y’ = converted measurement
y = original measurement
c = conversion factor
Variance (s2) and standard deviation (s): the spread of the measurements

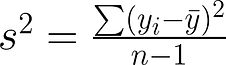

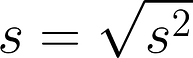
Numerator of variance equation is called the “sum of squares” and is the basis of most basic statistics.
Median: middle measurement in a sorted list of all measurements (similar utility as the mean)
Interquartile range: middle 50% of the measurements (similar utility as standard deviation). Special rules for calculating quartiles included in lesson .Rmd

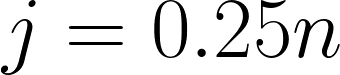
Median

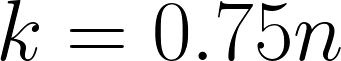

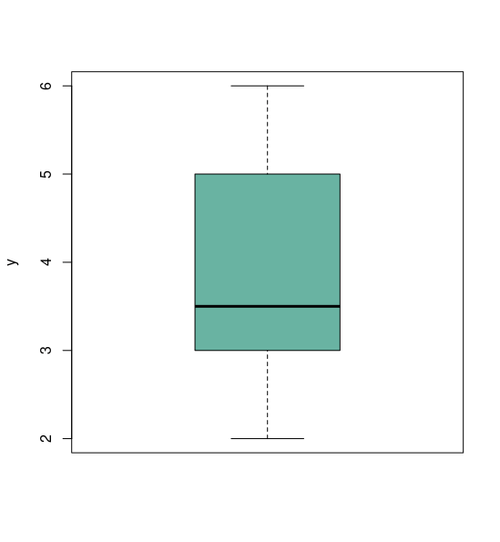
Box plot: displays the median as well as the interquartile range.

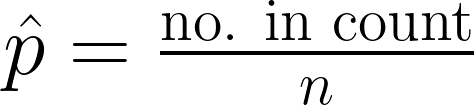
Proportions: the relative amount of a particular measurement from a particular group.