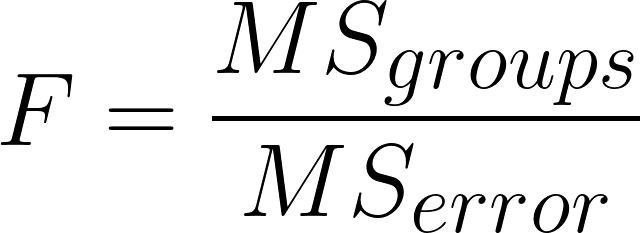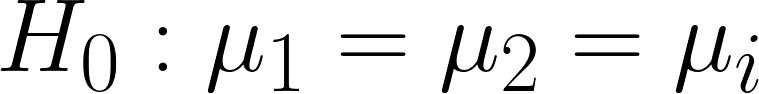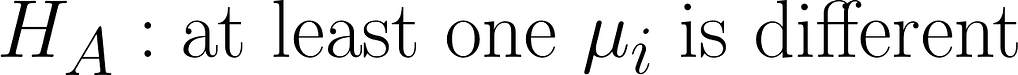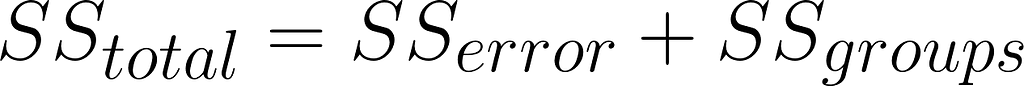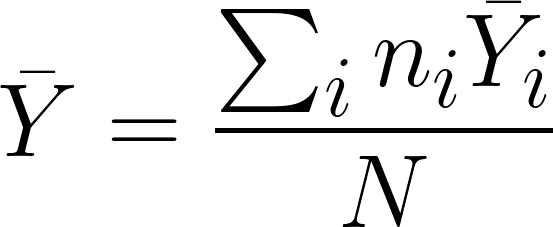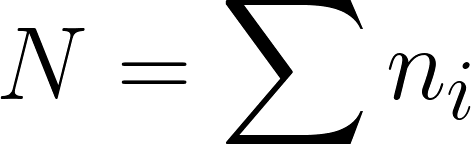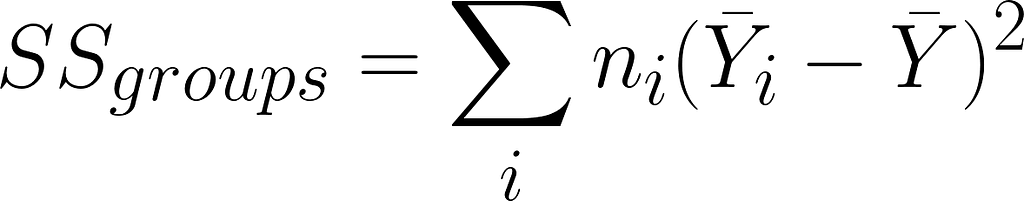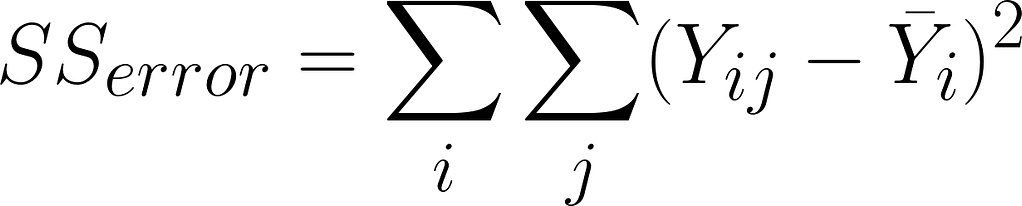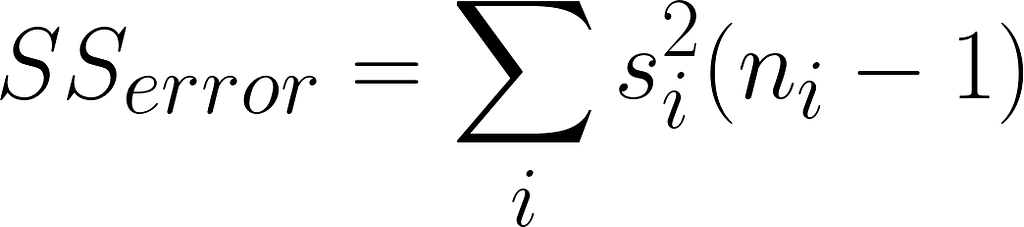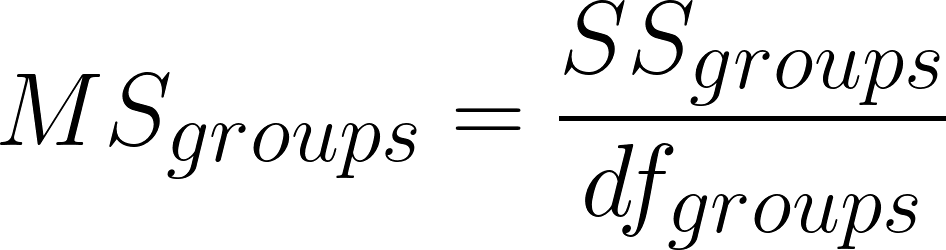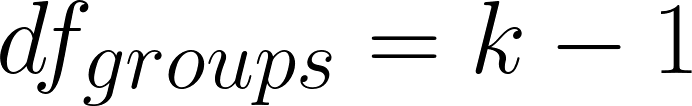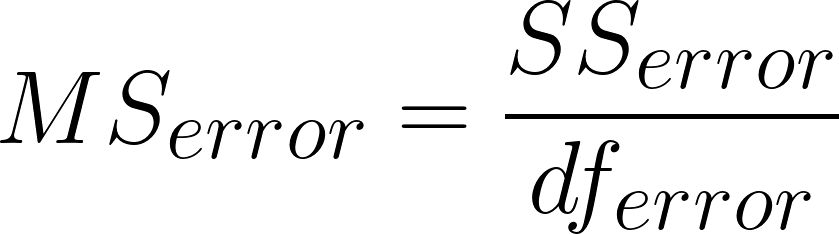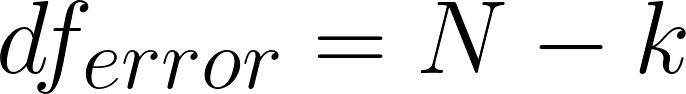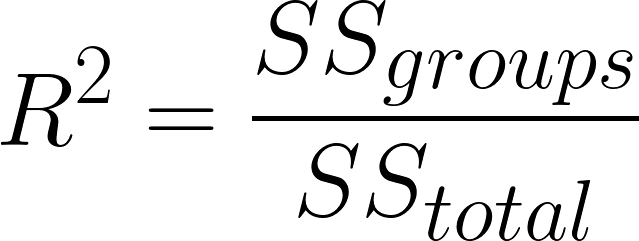We can use the analysis of variance (ANOVA) is a special type of non-parametric test used to compare means between normally distributed populations from more than groups.
ANOVA basics
Assumptions:
Samples are taken randomly
Measurements from each population is normally distributed
The variances are equal between all populations
MSgroups: mean square of groups
MSerror: mean square of error
Calculating the ANOVA test statistic
Step 1: Partition the sum of squares
Calculate a grand mean by taking the sum of the product of the means and sample size of each group divided by the N total number of observations.
Sum of squares of the groups
Sum of squares of the error
or
Step 2: Calculate the mean squares
Mean square groups
Mean square error
k = number of groups
Step 3: Build ANOVA table
Source of variance
Sum of squares
df
Mean squares
F
P
Groups
SSgroups
groups – 1
MSgroups
MSgroups / MSerror
P-value
Error
SSerror
observations – groups
MSerror
Total
SStotal
dferror + dfgroups
Step 4: If the null is rejected, perform a post-hoc test to determine differences between groups
This can be done using a Tukey-Kramer test
Determining the variance explained by differences in groups
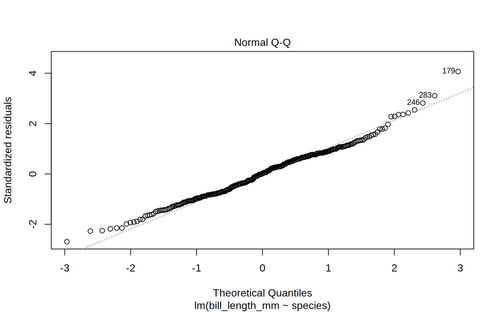
Checking assumptions
The normality assumption can be checked visually by looking at a Q-Q plot of the residuals. If the points fit the straight line well, we can claim that they are normally distributed.
Homogeneity of variances can be checked either by using a Levene’s test or Bartlett’s test.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.